基于小样本LoRA微调的混合式响应LLM实践探索
一、研究背景与动机
在大语言模型(LLM)应用日益广泛的今天,如何让模型的输出更加透明、自然且易于理解,成为了一个重要的研究方向。传统的LLM通常直接输出最终答案,其内部的推理过程对用户而言是一个"黑箱"。为了增强交互的可解释性,我们探索了一种**混合式响应**机制。
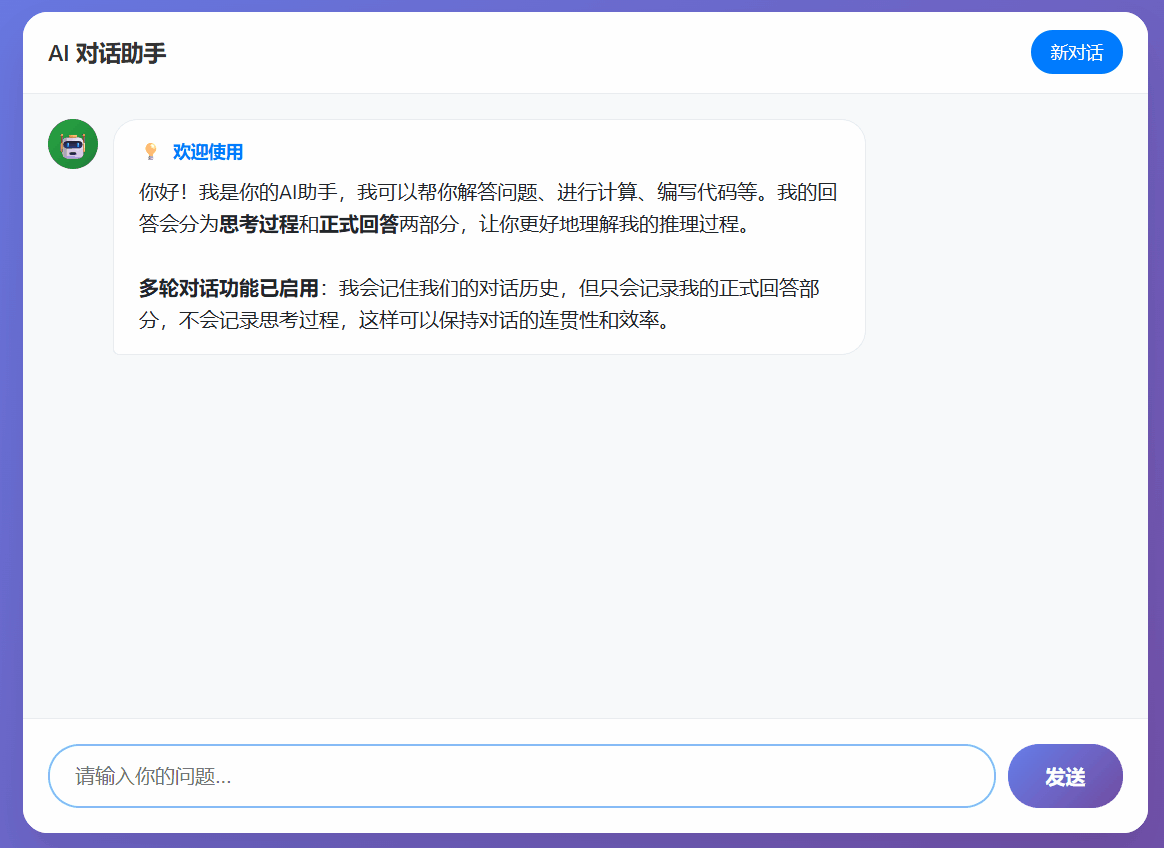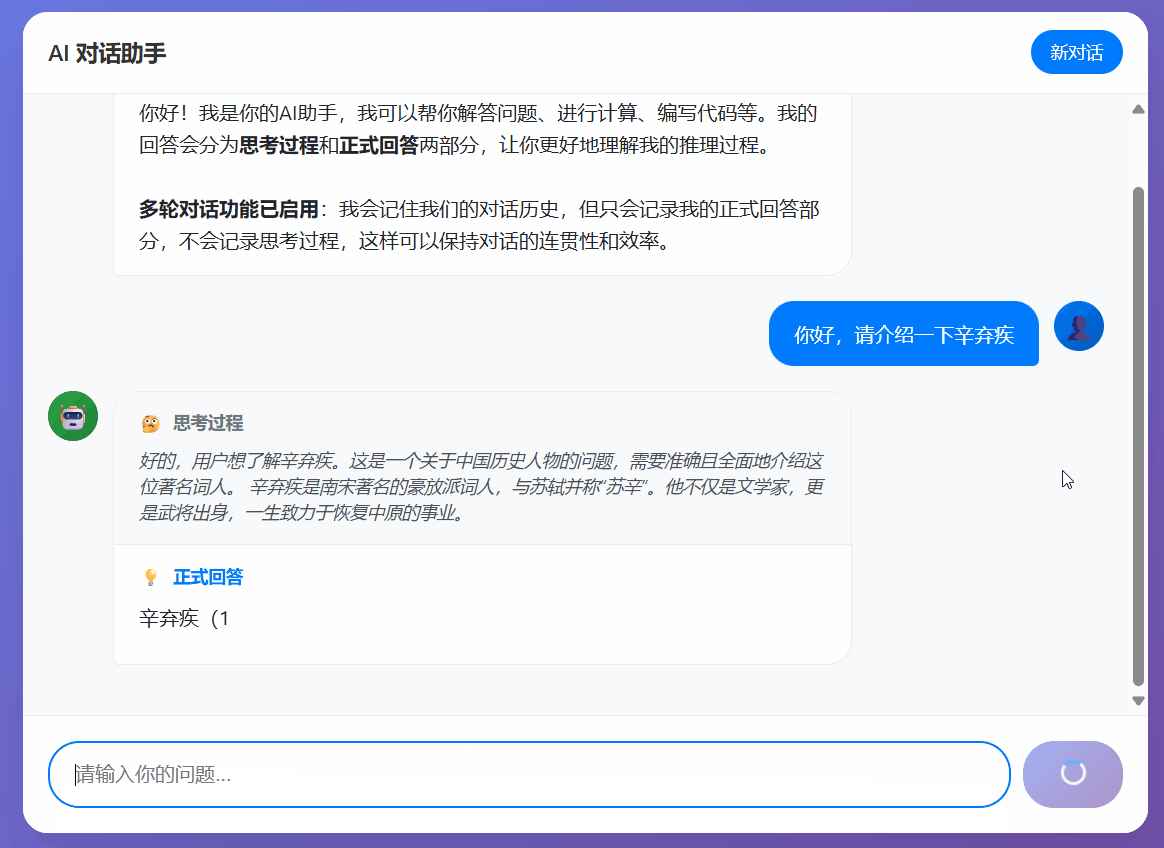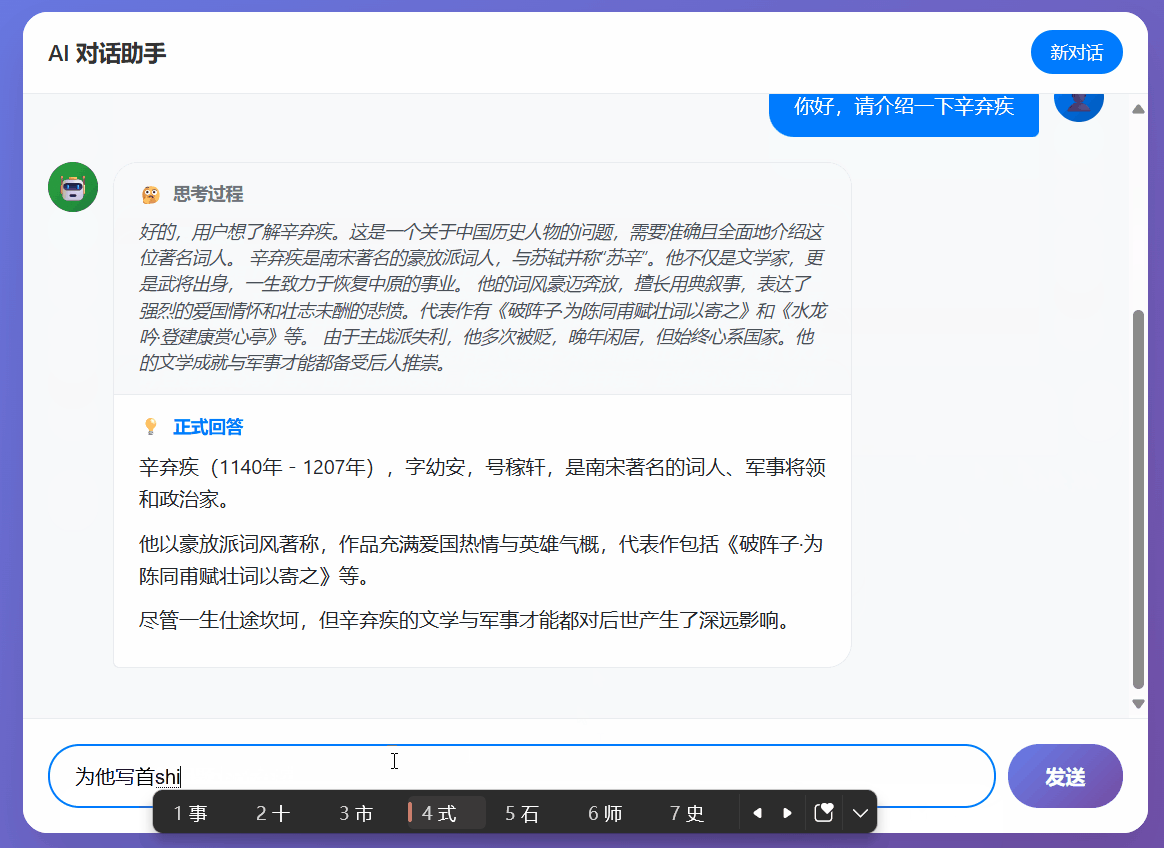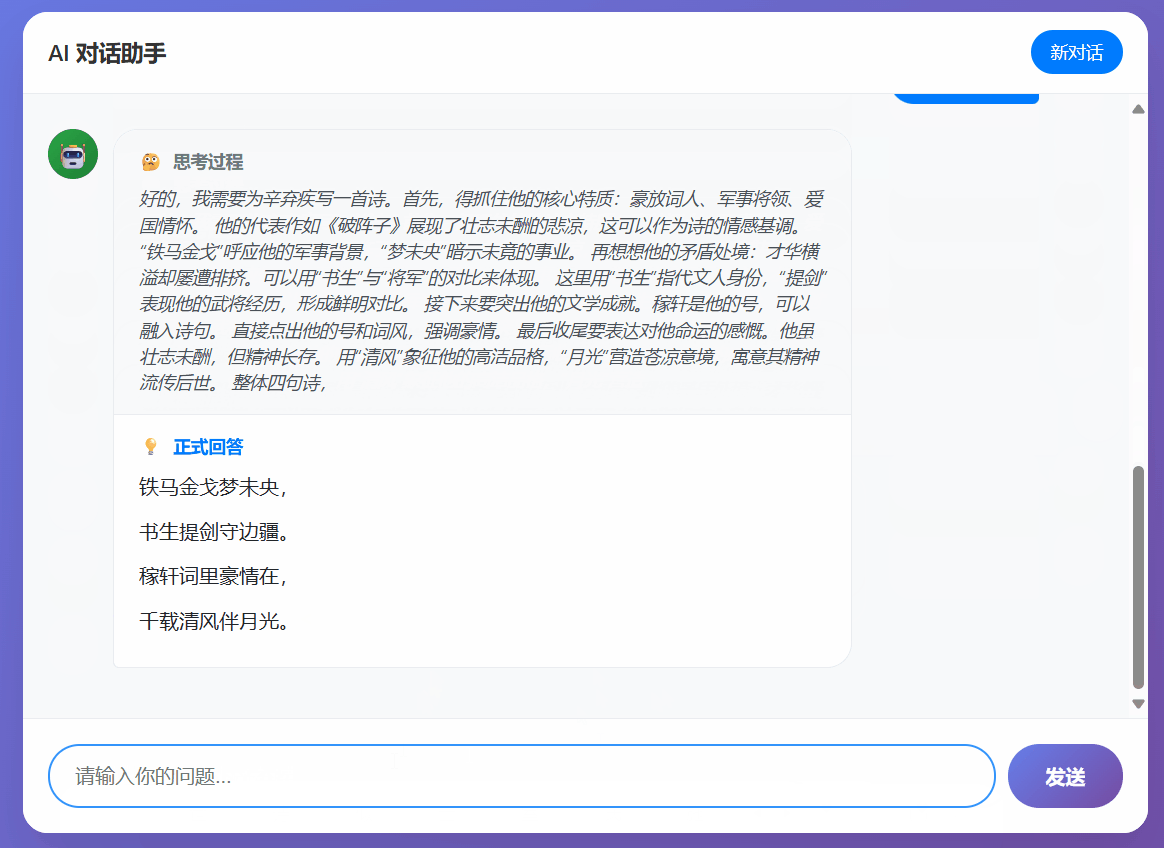
该机制的核心思想是让模型的响应模仿人类"边想边说"的模式,由"内部思考"和"对外回答"两部分交替组成。其中:
- 内部思考:是模型实时的推理过程,包括问题分解、逻辑推理和事实核查
- 对外回答:是模型呈现给用户的最终结论或阶段性答案,使用特定的标签 <|answer_start|> 和 <|answer_end|> 进行包裹。
我们的目标,并非从头训练一个具备此能力的新模型,而是希望通过高效的微调技术,让一个现有的通用大模型学会这种复杂的响应格式。
二、研究方法与过程
1. 模型与基座选择
我们选择了 Qwen3-14B 作为基础模型。这是一个性能强大且开源的140亿参数模型,具备良好的通用知识和推理能力作为基础。
2. 微调技术与数据集
- 微调技术:我们采用了 LoRA(低秩适应) 技术。LoRA的优势在于它能以极高的参数效率对大型模型进行微调,只需训练模型中原有参数的一个低秩分解子集,极大地降低了计算成本和硬件需求,非常适合快速迭代和实验。
- 数据集:我们精心构建了一个包含 1000条 样本的数据集。每条样本都严格遵循混合式响应规则,包含了交替出现的内部思考和带有标签的对外回答,旨在教导模型学会这种特定的输出格式。
3. 训练与挑战
训练过程专注于让模型学会两件事:一是如何进行有效的"内部思考"来推进问题解决;二是在何时、以何种节奏插入对外回答的标签。由于数据集规模较小(仅1000条),我们面临的主要挑战是确保模型能牢固掌握这一复杂规则,并具备良好的泛化能力。
数据集:dianzinao/deepseek-v3-distill-RWA-1000
三、研究结果与观察
经过LoRA微调后,我们在测试中观察到以下结果:
- 单轮对话效果良好:在单次问答场景下,微调后的模型效果还不错。它能够成功地按照既定规则,生成逻辑连贯的内部思考过程,并准确地在关键节点使用 <|answer_start|> 和 <|answer_end|> 标签输出回答片段。这证明了即使在小样本数据集上,LoRA微调也能有效教会模型一种新的、复杂的输出风格。
- 多轮对话存在明显局限:正如我们预料的,由于数据集规模有限且可能未专门针对多轮对话进行优化,模型在连续对话中效果较差。一个典型的问题是模型可能会遗忘添加回答标签,或者在后续轮次中回复模式退化回基础的对话风格,无法持续维持混合式响应的规则。这表明模型对规则的掌握尚未深入到能够处理更复杂的对话状态。
四、在线演示与总结
我们将此微调后的模型部署在了在线网站,供大家体验和交流:
🌐 演示地址:https://chat.dianzinao.cn
总结:
本次实践成功地验证了使用小规模数据集(1000条) 和 LoRA微调 技术,为现有大模型(Qwen3-14B)注入混合式响应这一特定交互能力的可行性。模型在单轮对话中的表现达到了预期目标,证明了该技术路径的有效性。
同时,我们也清晰地看到了其局限性,尤其是在多轮对话中规则保持能力的不足。这为未来的工作指明了方向:要解决这一问题,可能需要扩大和丰富训练数据集,特别是加入更多多轮对话的样本,或者探索其他微调策略以加强模型对长期指令的遵循能力。
本研究为探索透明、可解释的AI交互方式提供了一个低成本、可复现的实践案例。